In the age of Large Language Models (LLMs), the promise of universal AI sometimes overshadows a critical reality: AI is only as good as its training data. This is particularly true for speech technology in the MENA region. While massive global models can often handle Modern Standard Arabic (MSA), they hit an immediate accuracy ceiling when confronted with the daily conversational reality of the Arab world. At intella, we fundamentally believe that enterprise-grade automation cannot succeed if its input is flawed. This is why we engineered our ASR/STT engine from the ground up to solve the dialectal gap, ensuring your mission-critical applications rely on data that is precise, comprehensive, and contextually rich.
##The Benchmark Reality: Dialects vs. Accuracy
The core issue lies in the historical focus of global tech giants on general Western languages, with Arabic often treated as an afterthought. Their ASR models are typically trained heavily on formal, written Arabic data (MSA), which is rarely used in high-volume settings like call centers or casual media. The performance drop-off is measurable, significant, and exposes any enterprise relying on non-native technology to substantial risk:
intellaVX (Proprietary Arabic ASR): 95.73% Accuracy
This gap demonstrates that relying on generic models results in up to 40% more errors in transcription (Word Error Rate, or WER) a flaw that invalidates automation efforts and strategic revenue goals.
Why Global LLMs Fail: The Dialectal Gap
The failure of general models is rooted in three technical challenges that an Arabic-first LLM must overcome:
-
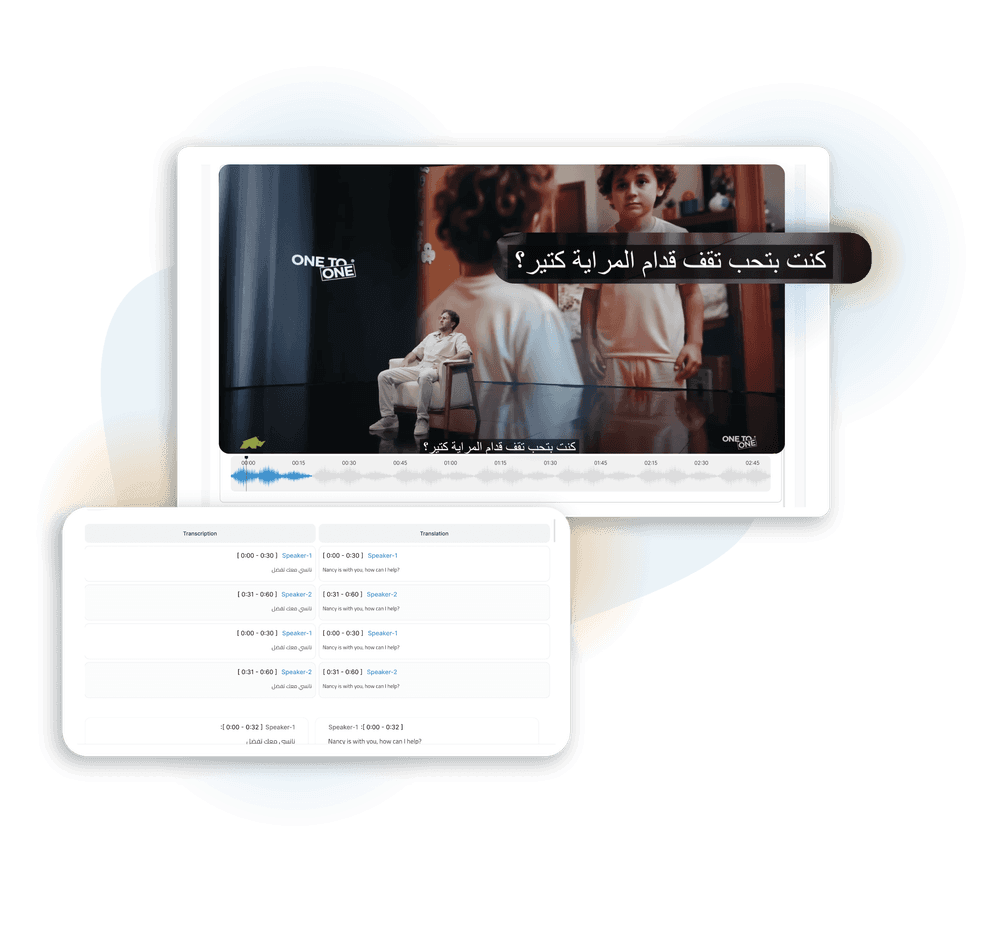
Conversational Dialectal Fluidity The Arabic language includes over 25 distinct conversational dialects. A global model trained primarily on MSA will struggle to accurately transcribe and interpret the subtle differences between Egyptian, Gulf, Levantine, or Maghrebi speech. Our engine is natively trained and verified on over 30,000 hours of publicly available Arabic voice audio files across more than 25 different Arabic dialects. This depth is the non-negotiable foundation for reliable transactional automation at scale.
-
Noise Robustness and Real-World Conditions AI deployed in real-world environments, such as busy call centers or outdoor recordings must deal with noise, varied audio quality, and different signal-to-noise ratios. Our models were specifically tested on a range of conditions starting from 40 decibels and reaching 110 decibels, ensuring a noise-robust performance that generic cloud providers simply cannot guarantee in the region.
-
Context and Cultural Nuance Transcription is only the first step. For true intelligence, the model must understand what was said and why. Our proprietary LLMs/SLMs are fine-tuned to grasp the cultural context and nuanced intent of the speaker. This Generative AI layer ensures that the output is not just accurate text, but actionable business insight (intellaCX) or the basis for autonomous decision-making (Ziila).
Engineered for Control: Deployment & Trust
For enterprises in regulated sectors (Finance, Government, Health Care), performance cannot come at the expense of control. intellaVX, our core engine, is designed to give you options tailored to strict security mandates:
Data Sovereignty: Our platform operates under the principle that data always belongs to the client. No client data is shared or used for third-party training. Flexible Deployment: We support Cloud or full On-Premise deployment, ensuring that your data residency requirements are met.
By building a specialized, Arabic-first ASR engine, intella has solved the dialectal gap, ensuring that our clients are building their next-generation AI solutions on the world’s most accurate and controllable foundation.